特征提取与特征选择。
Feature Extraction and Selection
特征提取问题:
有一串向量,$\{x_1,x_2,\cdots,x_p\}$,其中 $x_i=\{x_{i1},x_{i2},\cdots,x_{xN}\}$,每一个 $x_i$ 属于 $C_1$ 或 $C_2$。如果构造一个降维函数 $\{f_1(x_{i1}\sim x_{iN}),f_2(x_{i1}\sim x_{iN}),\cdots,f_M(x_{i1}\sim x_{iN})\}$,使其保留最大的可分类信息?
特征选择问题:
有一串向量,$x_1,x_2,\cdots,x_p$,其中 $x_i=\{x_{i1},x_{i2},\cdots,x_{xN}\}$,每一个 $x_i$ 属于 $C_1$ 或 $C_2$。$N$ 个维度有冗余,如何从 $N$ 个维度中选取 $M$ 个维度($M≤N$),使得识别率最高?
主成分分析(Principle Component Analysis)
主成分分析由卡尔·皮尔逊于 1901 年发明,用于分析数据及建立数理模型。
构造一个 $A$、$b$,使 $Y=Ax+b$,其中 $Y$ 是一个 Mx1 的矩阵,$X$ 是一个 Nx1 的矩阵,$A$ 是一个 MxN 的矩阵,$b$ 是一个 Mx1 的矩阵。即将 $X$ 由 N 维降至 M 维。故主成分分析可以看成是一个一层的有 M 个神经元的神经网络,且其中 $x$ 是没有标签(Label)的,和自编码器类似。
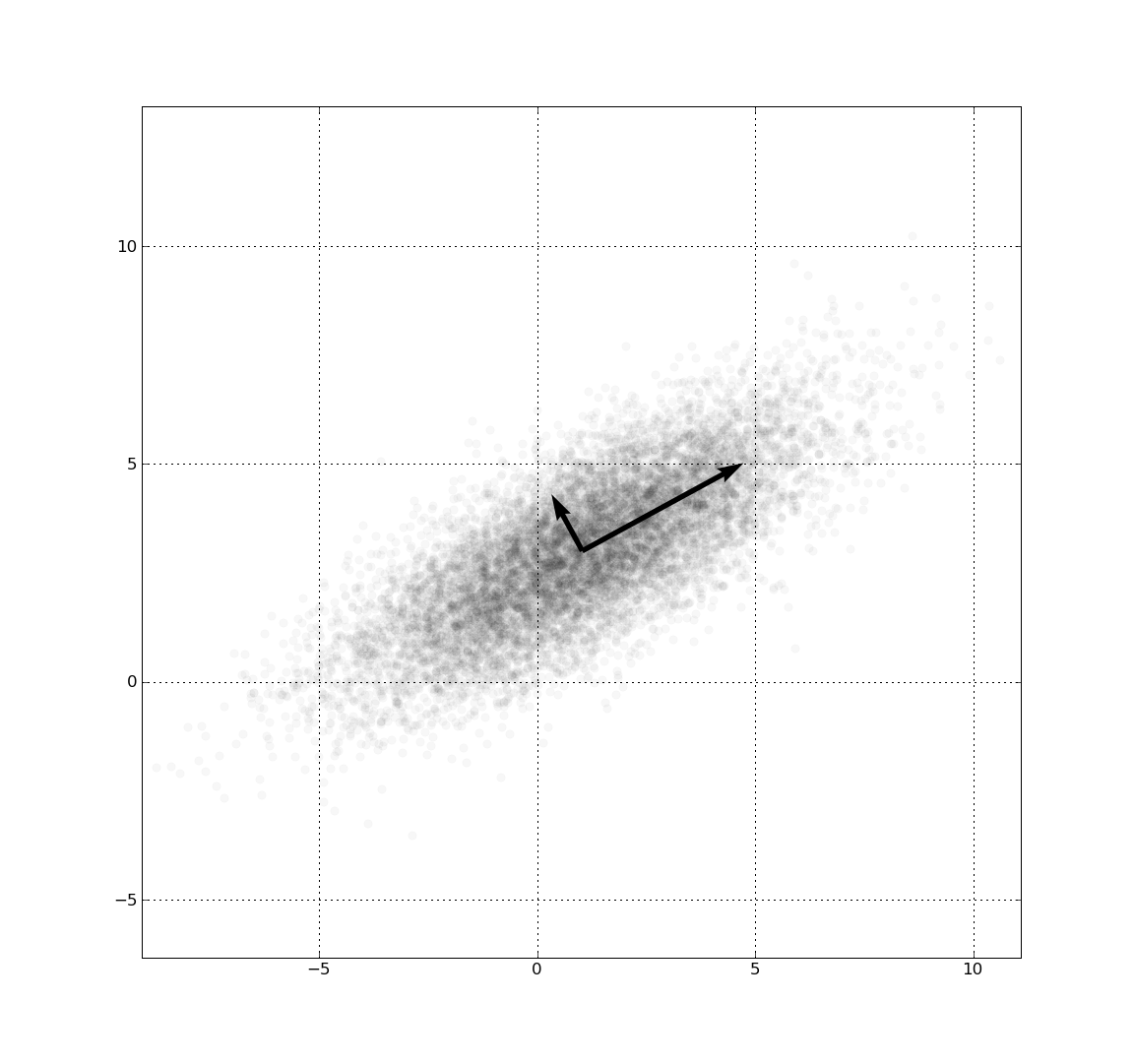
PCA 的做法:寻找使方差最大的方向,并在该方向上投影。最大限度地保存了训练样本的能量。
$$
\begin{cases}
Y=A(x-\bar{x}) & b=-A\bar{x}\\
\bar{x}=E(x)=\frac{1}{P}\sum_{p=1}^Px_p & \bar{x} 为x的均值
\end{cases}
$$
在 $Y=A(x-\bar{x})$ 中,$Y$ 是一个 Mx1 的矩阵,$A$ 是一个 MxN 的矩阵,$x$ 和 $\bar{x}$ 都是 Nx1 的矩阵。将 $A$ 写成行向量的形式,其中每个 $a_i$ 代表一个投影的方向:
$$
A=\begin{bmatrix}
a_1\\
a_2\\
\vdots\\
a_n
\end{bmatrix}
$$
那么 $Y$ 可以写成如下形式:
$$
Y_i=\begin{bmatrix}
a_1(x_i-\bar{x})\\
a_2(x_i-\bar{x})\\
\vdots\\
a_n(x_i-\bar{x})
\end{bmatrix}
=\begin{bmatrix}
y_{i1}\\
y_{i2}\\
\vdots\\
y_{iM}
\end{bmatrix}
(i=1\sim P)
$$
假设训练样本 $\{x_i\}{i=1\sim P}$。计算 $\bar{y{i1}}$ 的值如下:
$$
\begin{array}{l}
\bar{y_{i1}}=\frac{1}{P}\sum_{i=1}^Py_{i1}\\
\quad =\frac{1}{P}\sum_{i=1}^Pa_1(x_i-\bar{x})\\
\quad =\frac{a_1}{P}(\sum_{i=1}^Px_i-P\bar{x})=0
\end{array}
$$
最大化(其中 $\Sigma$ 是协方差矩阵):
$$
\begin{array}{l}
\sum_{i=1}^P(y_{i1}-\bar{y_{i1}})^2=\sum_{i=1}^Py_{i1}^2\\
\quad\quad\quad\quad\quad\quad =\sum_{i=1}^P[a_1(x_i-\bar{x})]^2\\
\quad\quad\quad\quad\quad\quad =\sum_{i=1}^P[a_1(x_i-\bar{x})][a_1(x_i-\bar{x})]^T\\
\quad\quad\quad\quad\quad\quad =\sum_{i=1}^Pa_1[(x_i-\bar{x})(x_i-\bar{x})^T]a_1^T\\
\quad\quad\quad\quad\quad\quad =a_1[\sum_{i=1}^P(x_i-\bar{x})(x_i-\bar{x})^T]a_1^T\\
\quad\quad\quad\quad\quad\quad =a_1\Sigma a_1^T & (\Sigma=\sum_{i=1}^P(x_i-\bar{x})(x_i-\bar{x})^T
\end{array}
$$
最终得到最大化优化问题如下:
- 最大化:$a_1\Sigma a_1^T$
- 限制条件:$a_1a_1^T=\lVert a_1\rVert^2=1$
拉格朗日乘子法:
$$
\begin{array}{l}
E(a_1)=a_1\Sigma a_1^T-\lambda(a_1a_1^T-1)\\
\frac{\partial E}{\partial a_1}=(\Sigma a_1^T-\lambda a_1^T)^T=0
\end{array}
$$
因此:
$$
\begin{array}{l}
\Sigma a_1^T=\lambda a_1^T & (a_1^T是\Sigma的特征向量,\lambda是\Sigma的特征值)\\
a_1(\Sigma a_1^T)=a_1(\lambda a_1^T)=\lambda(a_1a_1^T)=\lambda
\end{array}
$$
故可以得出 $\lambda$ 是 $\Sigma$ 最大的特征值,$a_1$ 是 $\Sigma$ 最大特征值对应的特征向量,且 $a_1a_1^T=1$。
改造优化问题:
- 最大化:$a_2\Sigma a_2^T$
- 限制条件:
- $a_2a_2^T=\lVert a_2\rVert^2=1$;
- $a_2a_1^T=a^1a_2^T=0$,即 $a_1$ 与 $a_2$ 正交。
拉格朗日乘子法:
$$
\begin{array}{l}
E(a_2)=a_2\Sigma a_2^T-\lambda(a_2a_2^T)-\beta a_1a_2^T\\
\frac{\partial E}{\partial a_2}=(\Sigma a_2^T-\lambda a_2^T-\beta a_1^T)^T=0\\
\Sigma a_2^T-\lambda a_2^T-\beta a_1^T=0
\end{array}
$$
证明 $\beta=0$:
$$
\begin{array}{cc}
(\Sigma a_2^T-\lambda a_2^T-\beta a_1^T)^T=0\\
a_2\Sigma^T-\lambda a_2-\beta a_1=0
\end{array}
$$
因为 $\Sigma$ 是一个对称阵,即 $\Sigma=\Sigma^T$,得到:
$$
\begin{array}{cc}
a_2\Sigma-\lambda a_2-\beta a_1=0\\
a_2(\Sigma a_1^T)-\lambda(a_2a_1^T)-\beta a_1a_1^T=0\\
a_2\lambda_1a_1^T-0-\beta=0\\
\lambda_1 a_2a_1^T-\beta=0\\
\beta=0
\end{array}
$$
由于 $\beta=0$,故有:
$$
\begin{cases}
\Sigma a_2^T=\lambda a_2^T\\
a_2a_2^T=1\\
a_2\Sigma a_2^T=\lambda
\end{cases}
$$
所以 $a_2$ 是 $\Sigma$ 的特征向量,$\lambda$ 是 $\Sigma$ 的第二大的特征值。以此类推,同理可以得到 $a_3$ 是 $\Sigma$ 第三大特征值特征向量;$a_4$ ……;$a_5$ ……
Summary
PCA 算法总结如下:
- 求协方差矩阵:$\Sigma=\sum_{i=1}^P(x_i-\bar{x})(x_i-\bar{x})^T$;
- 求协方差矩阵 $\Sigma$ 的特征值,并从大到小排序:$[\lambda_1,\lambda_2,\cdots,\lambda_M,\lambda_{M+1},\cdots]$,对应的特征向量:$[a_1^T,a_2^T,\cdots,a_M^T,a_{M+1}^T,\cdots]$;
- 归一化所有 $a_i$,使 $a_ia_i^T=1$;
- $A=\begin{bmatrix}a_1\\ a_2\\ \cdots\\ a_M\end{bmatrix}$;
- 降维:$Y_i=A(x_i-\bar{x})$,其中 $(i=1\sim P)$。
相关:SVD(Singular Value Decomposition)
自适应提升算法(AdaBoost)
自适应增强是一种机器学习方法,由 Yoav Freund 和 Robert Schapire 于 1995 年提出。
特征选择:$x=\begin{bmatrix}x_1\\ x_2\\ \cdots\\ x_N\end{bmatrix}$,从 N 个特征中选 M 个使识别率最高。共有 $C_N^M=\frac{N!}{M!(N-M)!}$ 种选法。启发式方法:
- 递增法;
- 递减法。
数据集 $T=\{(x_1,y_1),\cdots,(x_N,y_N)\}$,二分类问题:$y_i=\{-1,+1\}$。AdaBoost 算法流程:
- 输入:$T=\{(x_i,y_i)\}_{i=1\sim N}$;
- 输出:分类器 $G(x)=±1$。
- 初始化采样权值:$D_1=(\omega_{11},\omega_{12},\omega_{13},\cdots,\omega_{1N})$,且 $\omega_{1i}=\frac{1}{N}$,其中 $i=1\sim N$;
- 对 $m=1,2,\cdots,M$($M$ 是弱分类器个数),用 $D_M$ 采样 $N$ 个训练样本,在训练样本上获得弱分类器 $G_m(x)=±1$;
- 计算加权错误率:$\begin{array}{l}e_m=P(G_m(x_i)≠y_i)=\sum_{i=1}^N\omega_{m_i}I(G_m(x_i)≠y_i) & e_m<\frac{1}{2}\end{array}$,识别器 $G_m(x_i)$ 的权重为 $\begin{array}{l}\alpha_m=\frac{1}{2}\log\frac{1-e_m}{e_m} & \alpha_m>0\end{array}$;
- 更新权值分布:$D_{m+1}=\{\omega_{m+1,1},\omega{m+1,2},\cdots,\omega_{m+1,N}\}$,其中 $\begin{cases}\omega_{m+1,i}=\frac{\omega_{mi}}{Z_m}e^{-\alpha_my_iG_m(x_i)}\\ Z_m=\sum_{i=1}^N\omega_{mi}e^{-\alpha_my_iG_m(x_i)}\end{cases}$;
- 回到 2;
- 定义 $f(x)=\sum_{m=1}^M\alpha_mG_m(x)$,得到最终识别器 $G(x)=sign(f(x))=sign[\sum_{m=1}^M\alpha_mG_m(x)]$。
定理:随着 $M$ 增加,AdaBoost 最终的分类器 $G(x)$ 在训练样本上的错误将会越来越小。
- 错误率:$\begin{array}{l}E=\frac{1}{N}\sum_{i=1}^NI(G(x_i)≠y_i)≤\frac{1}{N}\sum_{i=1}^Ne^{-y_if(x_i)}\\ \quad=\Pi_{m=1}^MZ_m\end{array}$;
- $\begin{array}{l}E≤\frac{1}{N}\sum_{i=1}^Ne^{-\sum_{m=1}^M\alpha_my_iG_m(x_i)}\\ \quad=\sum_{i=1}^N\omega_{1i}\Pi_{m=1}^Me^{-\alpha_my_iG_m(x_i)}\\ \quad=\sum_{i=1}^M[\omega_{1i}e^{-\alpha_1y_iG_1(x_i)}][\Pi_{m=2}^Me^{-\alpha_my_iG_m(x_i)}]\\ \quad=\sum_{i=1}^M[\omega_{2i}Z_i][\Pi_{m=2}^Me^{-\alpha_my_iG_m(x_i)}]\\ \quad=Z_1\sum_{i=1}^M\omega_{2i}[\Pi_{m=2}^Me^{-\alpha_my_iG_m(x_i)}]\\ \quad=\Pi_{m=1}^MZ_m\end{array}$
证明:$Z_m=2\sqrt{e_m(1-e_m)}$
$$
\begin{array}{l}
Z_m=\sum_{i=1}^N\omega_{mi}e^{-\alpha_my_iG_m(x_i)}\\
\quad=\sum_{i=1\And y_i=G_m(x_i)}^N\omega_{mi}e^{-\alpha_m}+\sum_{i=1\And y_i≠G_m(x_i)}^N\omega_{mi}e^{\alpha_m}\\
\quad=(1-e_m)e^{-\alpha_m}+e_me^{\alpha_m}
\end{array}
$$
将 $\alpha_m=\frac{1}{2}\log\frac{1-e_m}{e_m}$ 代入,得:
$$
Z_m≤2\sqrt{e_m(1-e_m)}
$$
若 $e_m<\frac{1}{2}$,则 $Z_m<1$。
References
浙江大学信电学院《机器学习》课程